
We see a lot of opinions on ChatGPT, but in the end, what do we know? Just that it’s an artificial neural network with billions of parameters, capable of holding a high-level discussion, but also of falling into crude traps set by facetious Internet users. We hear a lot about it, but ultimately we know very little about how it works.
I therefore propose to present the main mechanisms on which ChatGPT is based and to show that, if the result is sometimes impressive, its elementary mechanisms are clever but not really new. To do this, let’s review the different terms of the acronym “ChatGPT”.
T like transform
A “transformer” is a neural network that benefits from the same learning algorithm as deep networks , which has already proven itself for training large architectures. It also benefits from two proven features: on the one hand, “lexical embedding” techniques for coding words; on the other hand, attentional techniques to take into account the fact that the words are sequential .
This second point is important for interpreting the meaning of each word in the context of the whole sentence. The technique proposed by the transformers favors a numerical and statistical approach, simple to calculate massively and very effective. This approach consists in learning, for each word and from the observation of numerous texts, which other words of the sentence must be “attention” to identify the context which can modify the meaning of this word. This allows you to match a word or replace a pronoun with the words of the phrase it represents.
G as generative
ChatGPT is capable of generating language: we present it with a problem and it responds to us with language – it’s a “language model”.
The ability to learn a generative model with a neural network is over thirty years old: in an autoencoder model , the output of the network is trained to replicate its input as closely as possible (e.g. a face image ), passing through an intermediate layer of neurons, chosen to be small: if the input can be reproduced through such a compact representation, it is because the most important aspects of this input (the nose, the eyes) are kept in the coding of this intermediate layer (but the details must be neglected because there is less room to represent the information). They are then decoded to reconstruct a similar face as output.
Used in generative mode, we choose a random activity for the intermediate layer and we obtain as output, through the decoder, something which will look like a face with a nose and eyes but which will be a new example of the phenomenon considered.
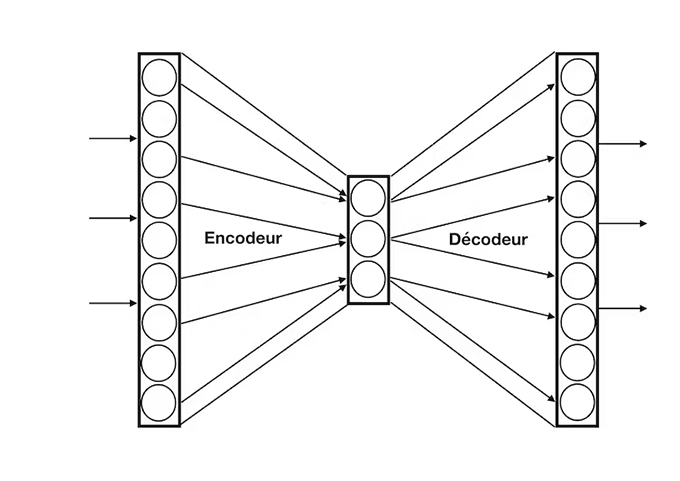
The layers of neurons of an auto-encoder model: the first layer receives the inputs, an intermediate layer encodes them in a more compact way and the last decodes them to find the original format. Frédéric Alexandre , Provided by the author
It is for example by following this process (with large networks) that we are able to create deepfakes , that is to say very realistic tricks.
If we now wish to generate sequential phenomena (videos or sentences), we must take into account the sequential aspect of the input stream. This can be obtained with the attentional mechanism described above, used in a predictive form. In practice, if we mask a word or if we look for the next word, we can predict this missing word from the statistical analysis of the other texts. As an illustration, see how well you are able to read a Smurfs comic and replace each “smurf” with a word from the attentional analysis of the other words.
The effectiveness of a simple attentional mechanism (which considers other important words in context but not explicitly their order) to process the sequential aspect of inputs has been a major finding in the development of transformers (“You don’t have need that attention” titled the corresponding publication: “Attention is all you need” ), because previously the preferred methods used more complex networks, known as recurrent, whose learning is comparatively much slower and less effective; moreover, this attentional mechanism parallelizes itself very well, which accelerates this approach all the more.
P as in pretrained
The effectiveness of transformers is not only due to the power of these methods, but also (and above all) to the size of the networks and the knowledge they ingest to train.
Quantified details are difficult to obtain, but we hear about transformers with billions of parameters (of weight in neural networks); to be more effective, several attentional mechanisms (up to a hundred) are built in parallel to better explore the possibilities (we speak of “multi-head” attention), we can have a succession of about ten encoders and decoders, etc.
Remember that the deep network learning algorithm is generic and applies regardless of the depth (and width) of the networks; it is enough to have enough examples to train all these weights, which refers to another disproportionate characteristic of these networks: the amount of data used in the learning phase.
Here too, little official information, but it seems that whole sections of the internet are sucked in to participate in the training of these language models, in particular the whole of Wikipedia, the several million books that we found on the Internet (of which versions translated by humans are very useful for preparing translation transformers), but also most likely the texts that can be found on our favorite social networks.
This massive training takes place offline, can last for weeks and use excessive computational and energy resources (estimated at several million dollars, not to mention the environmental aspects of CO₂ emissions associated with these calculations ).
Chat like chatting
We are now in a better position to present ChatGPT: it is a conversational agent, built on a language model which is a pre-trained generative transformer (GPT).
Statistical analyzes (with attentional approaches) of the very large corpora used make it possible to create sequences of words with very good quality syntax. Lexical embedding techniques offer properties of semantic proximity that give sentences whose meaning is often satisfactory.
In addition to this ability to know how to generate good quality language, a conversational agent must also know how to converse, that is to say, analyze the questions that are asked and provide relevant answers (or detect pitfalls to avoid them) . This was undertaken by another phase of offline learning, with a model called “InstructGPT”, which required the participation of humans who were playing the conversational agent or pointing out topics to avoid. . In this case, it is a matter of “learning by reinforcement” : this makes it possible to select responses according to the values given to them; it’s a kind of semi-supervision where humans say what they would have liked to hear (or not).
ChatGPT does what it was programmed to do
The characteristics set out here make it possible to understand that the main function of ChatGPT is to predict the most probable next word from the many texts it has already seen and, among the various probable sequences, to select those that in general humans prefer.
This sequence of processing may include approximations, when statistics are evaluated or in the decoding phases of the generative model when new examples are constructed.
This also explains phenomena of reported hallucinations, when asked for someone’s biography or details about a company and when he invents figures and facts. What he was taught to do is construct plausible and coherent sentences, not truthful sentences. You don’t have to understand a subject to know how to talk about it eloquently, without necessarily giving any guarantee on the quality of your answers (but humans also know how to do that…).
Author Bio: Frederick Alexander is Research Director in Computational Neuroscience at the University of Bordeaux, Inria