
A month or two ago, I wrote a post called ‘The Uneven U’ which outlined ideas about paragraph structure from Eric Hayot’s book “The elements of academic style: writing for the humanities”. Briefly, Hayot claims that there are five levels of abstraction in sentence structure:
Level five: Abstract; general, oriented toward a solution or conclusion
Level Four: Less general; orientated toward a problem; pulls ideas together
Level Three: Conceptual summary; draws together two or more pieces of evidence, or introduces a broad example.
Level Two: Description; plain or interpretive summary; establishing shot
Level One: Concrete; evidentiary; raw; unmediated data or information
Hayot suggests that paragraphs that are most successful at conveying information have an ‘uneven U’ structure, beginning at 4 (moderately abstract), going down through the levels to 1 (the most concrete), then back up to five (the most abstract). On a graph, the Hayot curve looks like this:
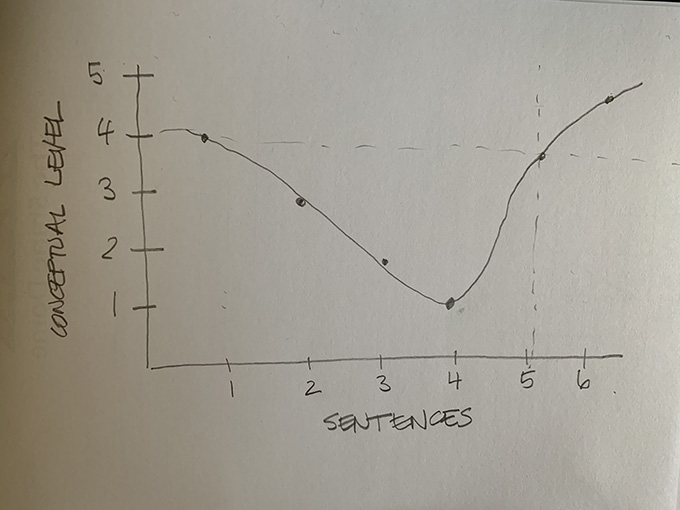
I’ve been teaching this concept since late last year and PhD students in my writing workshops tell me that they find it useful – if a bit difficult to operationalise. Most of my writing practice is based on teaching people to deconstruct other tests on the general principle that seeing how people in your own discipline do it can help you to better copy the ‘moves’ – and thus become a better writer, in that discipline at least. The trick to operationalising the Uneven U is to know how to write each type of sentence so you can start to see your writing process as a movement between abstract and concrete modes.
To help develop this ability to move between abstract and concrete, I suggest that people spend a bit of time with their favourite papers and graph paper to see if they can see this structure in action. I demonstrate how to deconstruct a paragraph by labelling each sentence on the Hayot scale then plotting it out as in the image above. In practice, I find defining a sentence at level 4 or 3 can be a bit subjective, but your mapping doesn’t have to be super precise to be useful. When you do this process for a page or so, you can start to see a pattern, but in all likelihood, it won’t be neat and tidy.
Take this abstract from a paper I was casually reading the other day: Mäntylä, M. V., Graziotin, D., & Kuutila, M. (2018). The evolution of sentiment analysis—A review of research topics, venues, and top cited papers. Computer Science Review, 27, 16-32. The paragraph is perfectly fine and corresponds with the ‘moves’ that Pat Thomson suggests are appropriate in an abstract:
Sentiment analysis is one of the fastest growing research areas in computer science, making it challenging to keep track of all the activities in the area. (Level 4) We present a computer-assisted literature review, where we utilize both text mining and qualitative coding, and analyze 6996 papers from Scopus (Level 2). We find that the roots of sentiment analysis are in the studies on public opinion analysis at the beginning of 20th century and in the text subjectivity analysis performed by the computational linguistics community in 1990’s (Level 2). However, the outbreak of computer-based sentiment analysis only occurred with the availability of subjective texts on the Web (Level 3). Consequently, 99% of the papers have been published after 2004. Sentiment analysis papers are scattered to multiple publication venues, and the combined number of papers in the top-15 venues only represent ca. 30% of the papers in total (Level 1). We present the top-20 cited papers from Google Scholar and Scopus and a taxonomy of research topics (Level 3). In recent years, sentiment analysis has shifted from analyzing online product reviews to social media texts from Twitter and Facebook (Level 4). Many topics beyond product reviews like stock markets, elections, disasters, medicine, software engineering and cyberbullying extend the utilization of sentiment analysis (Level 5).
Mapped on a piece of paper, this paragraph looks like this:
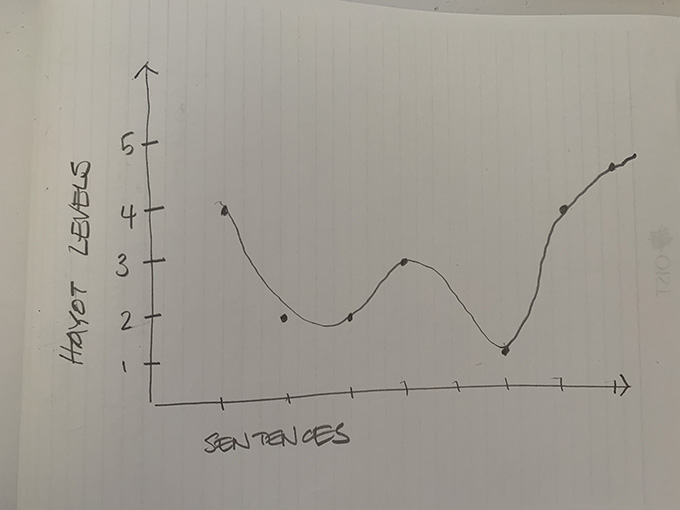
Most of the papers I advise students to map will not conform to a strict U shape, but this doesn’t mean the idea of moving between abstract and concrete is bunk. The curve in this graph is more like a roller coaster than an uneven U, although it does finish higher on the abstraction level than it starts (which corresponds with Hayot’s basic advice). This paragraph reads very well, despite not conforming strictly to Hayot’s curve, which suggests that movement from abstract to concrete and back again is more important than adhering exactly to the shape Hayot suggests. Any paragraph that shows up and down motion is still better than a paragraph that does not conform at all – but why?
To find out, we’re going to have to go into a bit of hairy theory (stay with me. The pay off is there, I promise). After I did my last post, Someone on Twitter (and I’m really sorry I can’t scroll back far enough to find out who) pointed me at literature on ‘Legitimation Code Theory’, remarking that they could see a resemblance. I book marked the link at the time, but, with life being busy I and all, I didn’t get to reading any of these papers until a couple of weeks ago. The prime mover behind Legitimation Code Theory (LCT) is a Sydney academic, Karl Maton. The basic idea, as outlined on his website, is to decipher the principles behind the ‘rules of the game’ in knowledge making practices and make the ‘DNA of knowledge’ more visible so that more people can access and participate in knowledge building. LCT attempts to operationalise observations by people like Pierre Bourdieu that social life has largely invisible ‘rules’ that tend to support and maintain certain kinds of power structures. To be honest, LCT seems pretty out there when you first read it, but I like the social justice angle and way people working in this mode draw on concepts from physics and chemistry to explain things like writing and comprehension.
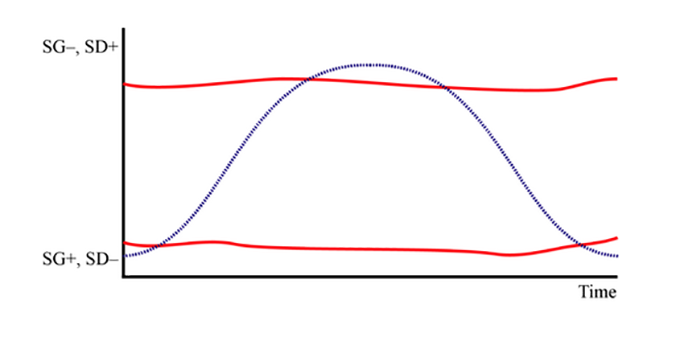
Using LCT applied to semantics (as outlined on this page), we could say that Hayot’s curve visualises the semantic density (complexity) and semantic gravity (context dependence) of each sentence, building ‘semantic waves’ that build knowledge over time. Maton visualises this process of construction as a graph, similar to Hayot:
You can think about semantic gravity as being closer too, or further away from, something concrete, be it a place, thing or data point. In my workshops I use a chair to demonstrate how to think about writing at different levels of semantic gravity. We start at the lightest setting, which means you are standing at a distance from any specific chair, from this distance you can only see chairs as a group:

A low semantic gravity sentence (level four or five on Hayot’s curve) talks about a lot of chairs at once: “Universities have to supply a lot of chairs for students, making the chair buying budget a significant capital expense”. Personally, I would call this a level 4 sentence because it’s oriented towards a specific problem. The semantic density is correspondingly high too: we’d have to know what a ‘capital expense’ means to reach full comprehension.
We can increase semantic gravity by mentally ‘zooming in’ on a smaller cluster of chairs, like this:

Image by @antenna on Unsplash
A sentence with higher semantic gravity (more context dependant) would go something like this: “Purchasing chairs for universities are exposed to a range of wear and tear factors as we cannot prevent students from doing things like resting their legs on the seats or spilling coffee, therefore purchasing decisions must be carefully considered”. I would call this a level two or level three sentence on Hayot’s curve: it describes a particular setting or data point, without being too specific. The semantic gravity might be higher, but the semantic density is lower: the sentence is easier to understand, perhaps because we can visualise actual events (a late student spilling their coffee).
To get down to level one on Hayot’s scale, or to the highest semantic gravity setting, we have to focus in on one chair in particular. For this I go to my friend Tseen Khoo’s project Sad Chairs of Academia, a Tumblr blog with the tagline of “You think you’re having a hard time in academia, but have you ever thought of the chairs? Will no-one think of the chairs?”. You do wonder why no one thinks of the chairs when you see pictures like this
That poor chair! Clearly it has had a hard life! We are now right up close to a concrete thing, place, person, quote, data point or whatever. A sentence with the gravity turned all the way up is a level one sentence on the Hayot curve, something like: “Chairs with fake leather covers are particularly prone to problems of long term problems of wear and tear; after ten years the covers are likely to have worn off the arms and seats, although the back rest of the chair might be less affected.” A level one sentence has the lowest semantic density – it is the simplest sentence to understand because it is the most concrete.
Once you have hit level one you must bounce up again through the levels of abstraction to help the reader see the ‘big picture’ again, quite literally when you think about it… Remember the movement is more important than the exact levels of each sentence and you should be able to put this ‘hidden rule’ of writing into action. I hope this detour into theory and broken chairs has helped illuminate the concept of semantic gravity – although I acknowledge it might be too out there and just leave you more confused than ever! Happy to try to answer questions in the comments.