Every day, thousands of web pages disappear without a trace. And with them, memories, knowledge, and fragments of our history vanish. When everything seems just a click away, it’s paradoxical that the World Wide Web (WWW) we call the Internet—that immense digital archive of our global civilization—is silently evaporating.
From clay tablets to broken links
Nearly 4,000 years ago, a merchant wrote a complaint about defective copper ingots on a clay tablet. That complaint has survived to this day. However, blogs, forums, and personal websites published just fifteen years ago have disappeared. How is it possible that a Bronze Age complaint is more enduring than a post from 2009?
The key lies in the fragility of the internet. Digital content, if not actively preserved, is by nature ephemeral.
Unlike physical media such as clay, papyrus, or paper, websites depend on servers that require maintenance, domains that need to be renewed, and formats that sooner or later become obsolete.
When a server disappears, a domain expires, redirects are mismanaged, or a website relies on obsolete technologies, the result is the same: content becomes inaccessible, and when it finally disappears, no one notices.
This phenomenon is called link rot , and it’s ongoing. An analysis of tweets I posted between 2007 and 2023 found that 13% of links were broken, and if the tweet was more than ten years old, the figure rose to 30%. In other words, nearly a third of the content linked to a decade ago has become inaccessible… if not completely gone.
The silent blackout
In Blade Runner 2049 , a massive blackout caused by replicant activists erases all digital records. But it doesn’t take such an extreme scenario for vast amounts of information to disappear in the blink of an eye. However, as in the film, these erasures are the result of conscious decisions, usually made by private companies. For example, the closure of platforms like Yahoo! Answers , Geocities , Tuenti , or the Meristation forums meant the loss of millions of texts, images, and conversations that documented part of our lives and our digital culture.
On the other hand, unlike previous administrations that implemented policies to preserve information available on government websites, the Donald Trump administration has systematically removed thousands of pages and official data from agencies such as the Centers for Disease Control and Prevention (CDC), the National Oceanic and Atmospheric Administration (NOAA), and the Environmental Protection Agency (EPA).
These deletions have primarily affected content related to public health, climate change, diversity, and social rights. They have led to a significant loss of public and scientific information and have generated alarm, particularly among the scientific community.
More information, but more ephemeral
All this is happening while more and more information (parliamentary minutes, official bulletins, scientific articles, and technical manuals, among others) is published in digital format, often without a physical copy.
The paradox is evident: our civilization produces more content than ever, but it does so in volatile formats and, furthermore, it is losing it faster than we imagine.
Despite this situation, there are efforts to preserve our digital memory. The most well-known is the Internet Archive’s Wayback Machine , which has archived billions of web pages since 1996. At the national level, institutions such as the National Library of Spain , or its equivalents in the United Kingdom and Australia, are also working to preserve part of our digital heritage.
What is being done (and what we could do)
Similarly, in the face of mass and deliberate deletions like those carried out by the Trump administration, various organizations are collaborating to archive deleted information. These initiatives seek to ensure future access to public data, not only for research purposes but also to preserve the historical record.
Of course, it’s not a simple task. Today’s WWW is much more complex than it was in the 1990s: content is dynamic and interactive, no longer simple HTML documents. Furthermore, archiving social media or multimedia content not only represents an enormous technical challenge, compounded by the obstacles imposed by the platforms themselves, but also raises ethical and legal dilemmas related to user privacy and consent. In other words, not everything can or should be preserved.
Still, we can all contribute: tools like the Wayback Machine’s “ Save Page Now ” or Archive.today allow anyone to archive a copy of any web page simply by entering its URL.
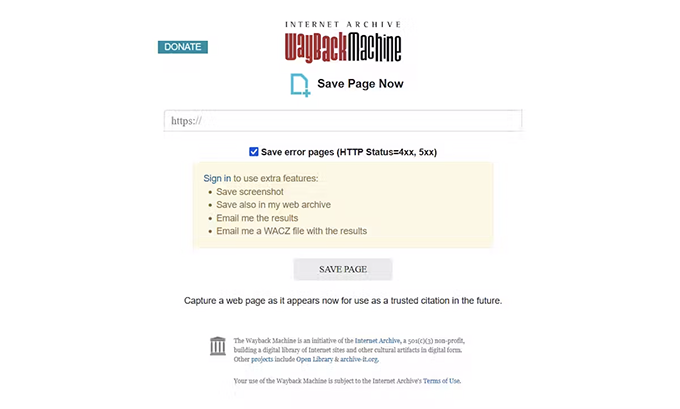
Screenshot of the Wayback Machine, with its Wayback Machine Internet Archive feature.
Digital legacy
Ultimately, saying that the WWW is rotting is like saying a forest is rotting: something always dies, but also something is born, since the network is constantly changing. The important thing is to know that we can capture fragments, preserve the essential, and build a more solid digital memory, less vulnerable to technological fluctuations or the decisions of a few companies or governments.
Maybe in 4,000 years, no one will find our complaints about faulty ingots, but they will find our recipes, memes, and forum discussions, and with them, a glimpse of who we were.
Author Bio: Daniel Gayo-Avello is Professor in the Department of Computer Science at the University of Oviedo